Gần đây, cộng đồng AI quốc tế đang dấy lên một nghi vấn đáng chú ý: DeepSeek – một phòng nghiên cứu AI tại Trung Quốc – có thể đã sử dụng dữ liệu đầu ra từ mô hình Google Gemini để huấn luyện cho phiên bản AI mới nhất của họ. Đây không chỉ là câu chuyện về công nghệ, mà còn liên quan đến đạo đức trong AI, tính minh bạch của dữ liệu huấn luyện và ranh giới giữa học hỏi và sao chép.

Câu chuyện bắt đầu từ đâu?
Tuần trước, DeepSeek công bố mô hình R1-0528, phiên bản nâng cấp của dòng AI tư duy lý luận R1. Mô hình này đạt kết quả cao trên nhiều bài kiểm tra về toán học và lập trình. Tuy nhiên, điều khiến giới nghiên cứu chú ý không nằm ở hiệu suất, mà ở nguồn dữ liệu huấn luyện mà DeepSeek không công khai.
Một số chuyên gia nghi ngờ rằng DeepSeek đã sử dụng output từ Gemini 2.5 Pro của Google – mô hình hàng đầu về ngữ cảnh dài và suy luận đa chiều – làm nguyên liệu huấn luyện.
Dấu hiệu cho thấy Gemini có thể đã bị khai thác
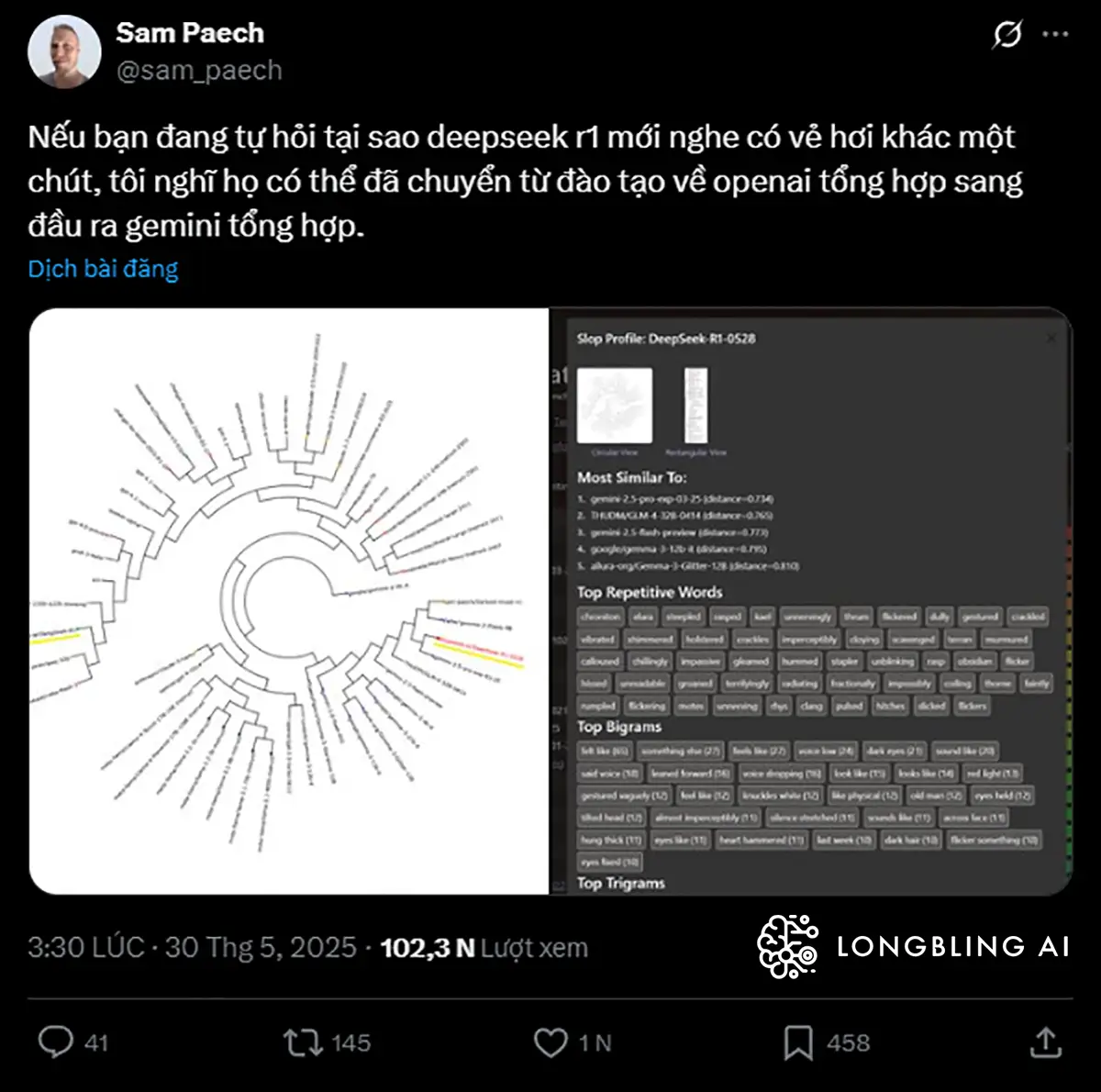
Sam Paech, nhà phát triển AI tại Melbourne, người chuyên tạo bài đánh giá trí tuệ cảm xúc cho mô hình AI, đã đăng tải bằng chứng cho thấy DeepSeek R1-0528 sử dụng những cụm từ và cách diễn đạt rất giống với Gemini 2.5 Pro. Mặc dù không phải là bằng chứng rõ ràng, nhưng lại cho thấy dấu hiệu mô hình được huấn luyện trên đầu ra của Gemini.
Ngoài ra, một lập trình viên ẩn danh – người tạo ra công cụ đánh giá free speech cho AI tên là SpeechMap – cho biết: dấu vết logic (trace) mà R1-0528 để lại trong quá trình suy luận có cấu trúc gần như trùng khớp với Gemini.
DeepSeek từng có tiền sử tương tự
Đây không phải lần đầu DeepSeek bị nghi ngờ. Vào tháng 12/2024, giới phát triển phát hiện mô hình DeepSeek V3 nhiều lần tự nhận là ChatGPT, cho thấy có khả năng công ty này đã sử dụng log chat từ mô hình của OpenAI để huấn luyện lại.
Thậm chí, theo Financial Times, OpenAI đã từng phát hiện bằng chứng về việc DeepSeek sử dụng kỹ thuật distillation – trích xuất kiến thức từ các mô hình lớn như GPT hay Gemini để tạo ra mô hình nhỏ hơn nhưng vẫn hiệu quả. Microsoft – đối tác thân thiết của OpenAI – cũng từng ghi nhận việc dữ liệu bị lấy ra từ các tài khoản nhà phát triển được cho là có liên quan đến DeepSeek.
Distillation có vi phạm không?
Về bản chất, distillation không phải là bất hợp pháp – nó là một kỹ thuật phổ biến trong AI. Tuy nhiên, các công ty như OpenAI và Google đều cấm sử dụng output của mô hình để huấn luyện mô hình cạnh tranh, điều này đã được nêu rõ trong điều khoản dịch vụ.
Vấn đề nằm ở chỗ: rất khó để chứng minh nếu không có log nội bộ, vì các mô hình có thể dùng chung ngôn ngữ, chung dữ liệu web hoặc chịu ảnh hưởng bởi môi trường AI sinh ra từ AI.
Internet đang bị ô nhiễm AI?
Một điểm đáng lo ngại được các chuyên gia chỉ ra là: nội dung trên web ngày càng bị chi phối bởi AI, dẫn tới ô nhiễm dữ liệu. Hàng loạt nội dung từ Reddit, X (Twitter) hay các trang content farm đang được tạo ra bởi AI, rồi lại được các mô hình AI khác sử dụng làm dữ liệu học tập.
Hệ quả là việc lọc bỏ nội dung do AI sinh ra khỏi bộ huấn luyện gần như bất khả thi – và điều này khiến nghi vấn như vụ DeepSeek – Gemini khó kết luận dứt điểm.
Phản ứng từ các ông lớn AI
Trước nguy cơ bị khai thác, các công ty AI hàng đầu đã có những động thái phòng ngừa:
- OpenAI: Từ tháng 4/2025, yêu cầu người dùng tổ chức phải xác minh danh tính bằng giấy tờ hợp lệ mới được truy cập các mô hình nâng cao – và Trung Quốc không nằm trong danh sách quốc gia được hỗ trợ.
- Google: Bắt đầu tóm tắt hóa phần trace (hành vi tư duy nội tại) trong mô hình Gemini thông qua nền tảng AI Studio, giúp giảm nguy cơ trích xuất ngược để huấn luyện đối thủ.
- Anthropic: Tuyên bố từ tháng 5/2025 sẽ làm điều tương tự với các mô hình Claude của mình, nhằm bảo vệ lợi thế cạnh tranh.
Là người giảng dạy và ứng dụng AI trong đào tạo, tôi cho rằng vụ việc này không chỉ là vấn đề kỹ thuật, mà còn là bài học lớn về ranh giới đạo đức, minh bạch và trách nhiệm trong AI. Trong một kỷ nguyên mà mô hình AI có thể học từ chính nhau, sự ô nhiễm dữ liệu sẽ khiến việc đảm bảo công bằng và chính thống trở nên khó khăn hơn bao giờ hết.
Chúng ta cần những tiêu chuẩn rõ ràng, minh bạch và các công cụ giám sát độc lập để đảm bảo sự phát triển AI đi đúng hướng, không phải bằng cách sao chép thông minh mà bằng sáng tạo thực sự.